
Bernd Huber
Senior Research Scientist, Spotify
PhD Computer Science, Harvard University
📍 New York City
📧
Hi! I'm a Senior Research Scientist at Spotify, developing foundation models for preference learning and AI alignment at 700M+ user scale. I create novel architectures and training methodologies that enable learning from human feedback and interactions. My PhD at Harvard focused on dialogue systems and computational models of dialogue. I'm interested in the science of building AI that adapts to individual users. I developed Embedding-to-Prefix and lead the foundational research powering Spotify's AI experiences, including AI Playlist and AI DJ.
In The News
Thrilled to see my preference optimization work featured in the Q2 2025 earnings call as key AI strategy. [Summary, and Earnings call, starting at 10:50]
Publications
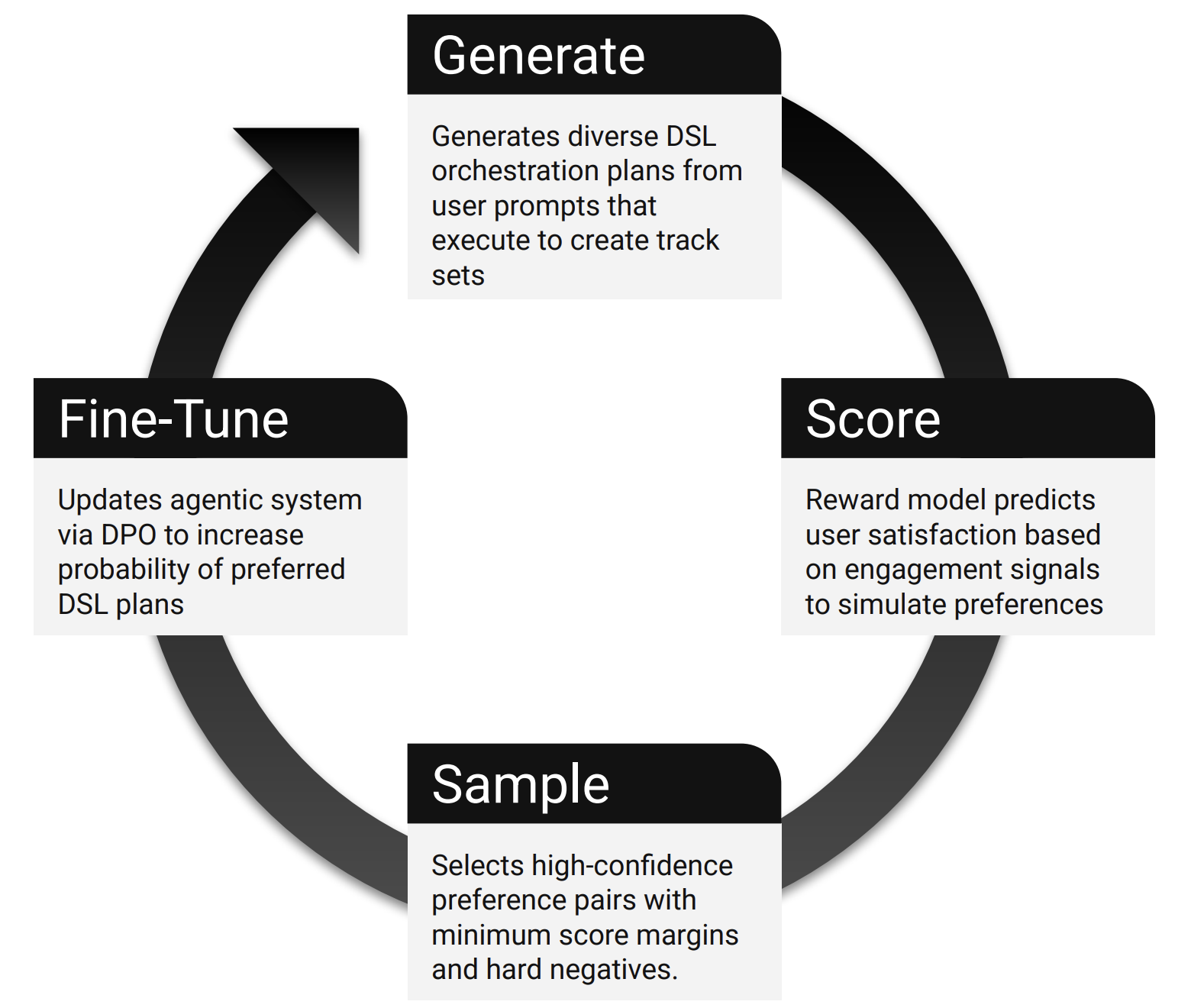
Personalizing Agentic AI to Users' Musical Tastes with Scalable Preference Optimization
Bernd Huber, Sebastian Peleato, Mounia Lalmas-Roellke, Paul N. Bennett
I developed a hybrid approach combining reward models and Direct Preference Optimization (DPO) to create LLM-based agentic systems that continuously learn from user feedback. This method enables AI systems to interpret musical queries, orchestrate tools, and adapt through preference learning, achieving 4% increase in listening time and 70% reduction in erroneous tool calls in production.
[Spotify Research, 2025]
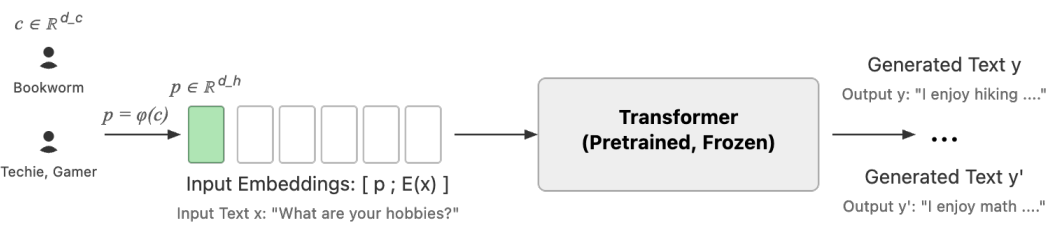
Embedding-to-Prefix: Parameter-Efficient Personalization for Pre-Trained Large Language Models
Bernd Huber, Ghazal Fazelnia, Andreas Damianou, Sebastian Peleato, Max Lefarov, Praveen Ravichandran, Marco De Nadai, Mounia Lalmas-Roellke, Paul N. Bennett
I developed a novel architecture that enables deep personalization of large language models using pre-computed user embeddings. This method bridges representation learning and generative AI, allowing foundation models to be steered by rich user context without costly fine-tuning. The approach achieves strong personalization while maintaining computational efficiency at scale.
[NeurIPS CCFM, 2025]
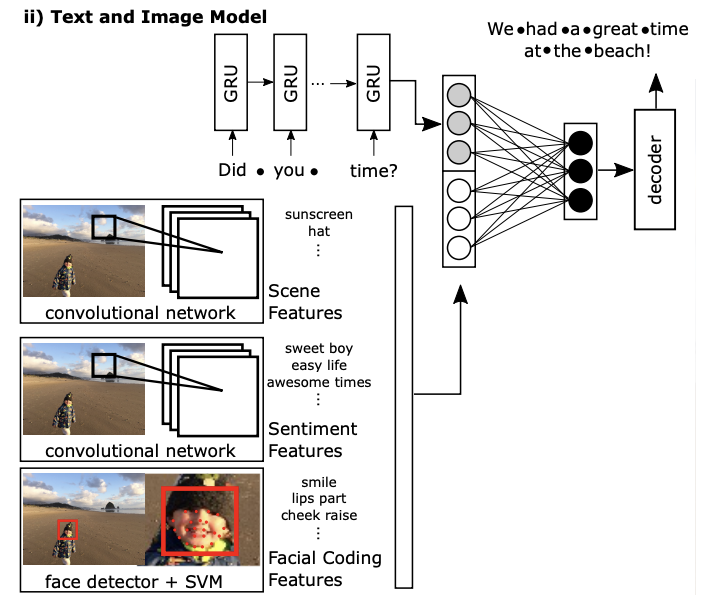
Emotional Dialogue Generation Using Image-Grounded Language Models
Bernd Huber, Daniel McDuff, Chris Brockett, Michel Galley, Bill Dolan
I built a multimodal dialogue system that generates contextually appropriate responses by jointly processing text and visual information. This work established foundational methods for incorporating visual sentiment and scene understanding into conversational AI, demonstrating how computational systems can respond to nuanced, multimodal human inputs.
[CHI, 2018]